
Introduction
In the evolving landscape of data engineering, organizations increasingly demand a unified platform that combines the flexibility of data lakes with the structure and performance of data warehouses. This is where the data lakehouse architecture shines, and Apache Iceberg emerges as a game-changing technology that makes this vision practical.
In this comprehensive guide, we'll explore how to build a production-ready data lakehouse architecture using Apache Iceberg, implementing CDC (Change Data Capture) replication from PostgreSQL, and organizing data into bronze, silver, and gold zones. We'll dive deep into practical implementation details including S3 bucket layout, data curation strategies, compaction, handling deletes, and modern data modeling approaches.
What is a Data Lakehouse?
A data lakehouse represents the convergence of data lakes and data warehouses. It provides:
- Flexibility: Store any data format in open standards
- Scalability: Handle petabyte-scale datasets economically
- Performance: Query data directly in cloud storage at warehouse speeds
- Data Quality: ACID transactions and schema enforcement
- Governance: Delta Lake, Apache Iceberg, or Apache Parquet provide these capabilities
Apache Iceberg stands out as the open-table format of choice, providing a hidden partitioning model, schema evolution, and excellent query performance.
Understanding the Bronze-Silver-Gold Architecture
The medallion (or multi-hop) architecture organizes data processing into three distinct layers:
Bronze Zone (Raw Data)
The bronze zone captures raw, unprocessed data directly from source systems. This layer acts as an immutable record of source data.
Characteristics:
- Minimal transformation applied
- Full historical data retention
- Schema may vary due to upstream changes
- CDC captures changes efficiently from PostgreSQL
- Optimized for append-only patterns
- Typically highest volume and lowest query frequency
Silver Zone (Cleaned and Unified Data)
The silver layer applies business logic, data quality rules, and combines data from multiple sources.
Characteristics:
- Consistent schema across similar data types
- Deduplication and data quality checks applied
- Historical changes tracked with slowly changing dimensions
- Optimized for analytical queries
- Reduced storage through compaction
- Query-friendly table structure
Gold Zone (Analytics-Ready Data)
The gold layer presents aggregated, business-aligned datasets optimized for specific use cases.
Characteristics:
- Business metrics and KPIs
- Pre-aggregated dimensions and facts
- Optimized schemas (star/snowflake)
- High query performance
- Governance and access control applied
- Smallest dataset size, highest value
CDC Replication Architecture: PostgreSQL to Iceberg
Change Data Capture enables efficient incremental data loading from PostgreSQL by capturing insert, update, and delete operations.
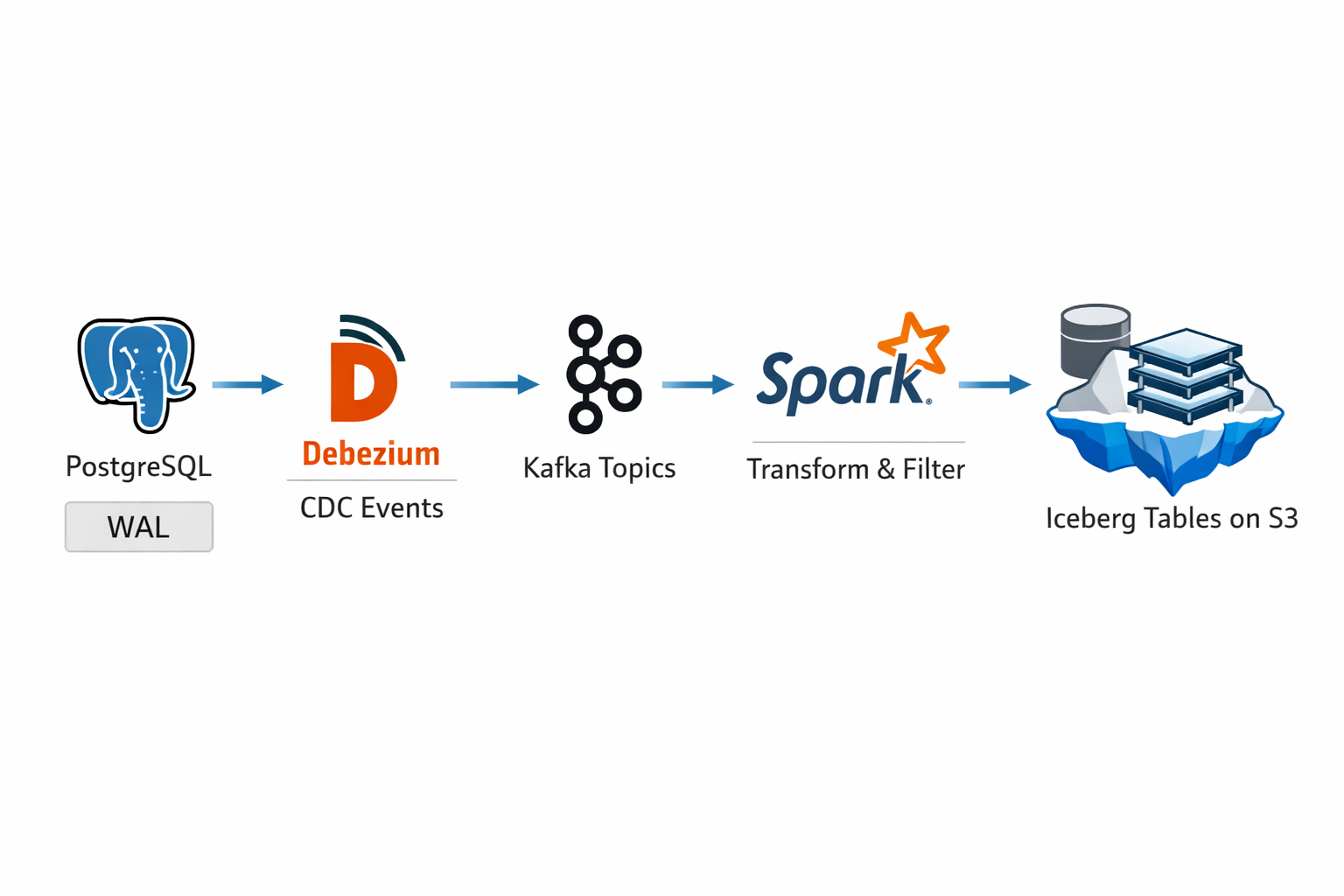
PostgreSQL Setup
-- Enable logical replication
ALTER SYSTEM SET wal_level = logical;
-- Create publication for CDC
CREATE PUBLICATION cdc_publication FOR ALL TABLES;
-- Create replication slot
SELECT * FROM pg_create_logical_replication_slot('cdc_slot', 'test_decoding');Handling CDC Events in Iceberg
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
spark = SparkSession.builder.appName("CDC-Iceberg").getOrCreate()
# Read CDC events from Kafka
cdc_df = spark.readStream \\
.format("kafka") \\
.option("kafka.bootstrap.servers", "kafka:9092") \\
.option("subscribe", "postgresql.public.customers") \\
.load()
# Parse CDC payload (Debezium format)
from pyspark.sql.types import *
cdc_df = cdc_df.select(
get_json_object(col("value").cast("string"), "$.op").alias("operation"),
get_json_object(col("value").cast("string"), "$.after").alias("data"),
get_json_object(col("value").cast("string"), "$.ts_ms").alias("cdc_timestamp")
)
# Write to Iceberg Bronze table
cdc_df.writeStream \\
.format("iceberg") \\
.mode("append") \\
.option("path", "s3://data-lakehouse/bronze/postgresql/customers/") \\
.option("checkpointLocation", "s3://data-lakehouse/checkpoints/customers/") \\
.start() \\
.awaitTermination()S3 Bucket Layout and Organization
Organizing S3 buckets effectively is crucial for maintainability, security, and cost optimization.

Recommended S3 Structure
s3://org-data-lake/
├── bronze/
│ ├── postgresql/
│ │ ├── customers/
│ │ ├── orders/
│ │ └── products/
│ ├── external-apis/
│ │ ├── weather/
│ │ └── market-data/
│ └── logs/
├── silver/
│ ├── fact_tables/
│ ├── dimension_tables/
│ └── integration/
├── gold/
│ ├── marketing/
│ ├── finance/
│ └── operations/
├── temp/
│ └── spark-jobs/
└── metadata/
└── schemas/Best Practices for S3 Organization
Partition by Zone, Date-Based Partitioning, Source Tracking, and Archive Strategy are key organizational patterns.
Data Curation in the Silver Zone
Data curation involves transforming raw data into reliable, trustworthy datasets.
Curation Pipeline Example
from pyspark.sql.functions import *
# Read from Bronze
bronze_customers = spark.table("bronze.postgresql_customers")
# Data Quality Checks
quality_checks = bronze_customers \\
.filter(col("email").isNotNull()) \\
.filter(col("customer_id") != "")
# Deduplication
curated_customers = quality_checks \\
.withColumn("row_num",
row_number().over(Window.partitionBy("customer_id")
.orderBy(desc("cdc_timestamp")))) \\
.filter(col("row_num") == 1) \\
.drop("row_num")
# Add curation metadata
silver_customers = curated_customers \\
.withColumn("curated_at", current_timestamp()) \\
.withColumn("data_quality_score", lit(0.95))
# Merge into Silver table (upsert)
silver_customers.writeTo("silver.customers") \\
.using("iceberg") \\
.whenMatched() \\
.updateAll() \\
.whenNotMatched() \\
.insertAll() \\
.execute()Compaction Strategy
Compaction is critical for maintaining Iceberg table performance by consolidating small files created during incremental updates.
Automatic Compaction with Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Compaction").getOrCreate()
# Compact Bronze tables
spark.sql("""
CALL system.rewrite_data_files(
table => 'bronze.customers',
strategy => 'binpack',
options => map('target-file-size-bytes', '536870912')
)
""")
# Remove orphaned files
spark.sql("CALL system.remove_orphan_files(table => 'bronze.customers')")Handling Deletes with Iceberg
Iceberg's delete support through position deletes ensures efficiency and data correctness.
# Direct Delete by ID
spark.sql("""
DELETE FROM silver.customers
WHERE customer_id = '12345'
""")
# Bulk Delete from Staging
spark.sql("""
DELETE FROM silver.customers
WHERE customer_id IN (SELECT customer_id FROM staging_deletes)
""")Data Modeling in the Lakehouse
Modern data modeling for lakehouses combines dimensional modeling with flexibility.
Slowly Changing Dimension Type 2
CREATE TABLE silver.dim_customers (
customer_key INT NOT NULL,
customer_id VARCHAR,
customer_name VARCHAR,
email VARCHAR,
start_date DATE,
end_date DATE,
is_current BOOLEAN
)
USING iceberg
PARTITIONED BY (year(start_date));Monitoring and Governance
Effective lakehouse management requires continuous monitoring and governance practices.
-- Table size and growth
SELECT
table_name,
ROUND(size_in_bytes / 1e9, 2) as size_gb,
row_count
FROM iceberg_metadata
ORDER BY size_in_bytes DESC;
-- Data freshness
SELECT
table_name,
MAX(loaded_timestamp) as latest_load
FROM bronze_tables
GROUP BY table_name;Best Practices Summary
- Isolate zones: Keep bronze, silver, and gold in separate logical areas
- Partition strategically: Use date and source partitioning for efficient queries
- Automate ingestion: Use managed CDC tools like Debezium for PostgreSQL
- Compact regularly: Schedule weekly compaction for all zones
- Version schemas: Track schema changes with Git or metadata tools
- Monitor quality: Implement automated data quality checks
- Encrypt sensitive data: Use column-level encryption in the lakehouse
- Archive cold data: Move old partitions to S3 Glacier for cost optimization
- Test transformations: Use staging areas for validation before production
- Document lineage: Maintain data lineage for compliance and debugging
Conclusion
Building a modern data lakehouse with Apache Iceberg, CDC replication, and the bronze-silver-gold architecture provides a robust foundation for scalable, governed analytics. By following the patterns and practices outlined in this guide—from S3 organization to data curation, compaction, delete handling, and dimensional modeling—organizations can create a platform that balances flexibility with structure, performance with cost-effectiveness.
The combination of Iceberg's reliability, PostgreSQL's CDC capabilities, and thoughtful architectural patterns transforms data infrastructure into a competitive advantage. Start with foundational bronze tables capturing raw data, progress through silver zone curation and integration, and deliver business value through gold zone analytics.
Your journey to a modern data lakehouse starts today.